论文题目
Learning Memory-guided Normality for Anomaly Detection
该文是发表在CVPR 2020的文章,MNAD指Memory-guided Normality for Anomaly Detection。文章相当于是MemAE的改进版,该文章主要在无监督异常检测领域考虑了异常情况在某种场景下不一定是异常的问题和CNN的表示能力过强导致信息过多丢失的问题。
Motivation
1.之前重建异常的方法没有考虑到多种场景的异常检测问题
异常并不总是在所有情况下都是异常,比如说在公园拿着刀检测为异常,在厨房拿着刀就不会。并且异常数据往往是小样本,场景具有较大的不确定性。所以说异常是根据场景的不同来确定是否是异常的。
2.之前的方法由于CNN特征提取过度导致重建模糊
之前的方法(AE,MemAE等)由于是直接利用encoder的embedding进行,没有考虑输入同类型的正常之间的变化,也没有解决对于CNN通道容量太大导致的重建模糊问题。
Contribution
1.增加了attention机制的更新模块
与MemAE一样,本文使用了记忆项来存储多个多种典型的场景,与MemAE不同的是,本文对Memory中的项与项之间进行了seperate的操作,并且在重建时对输入embedding和记忆项输出embedding进行拼接。
2.实现异常在多样性场景的区分
文章中引入了feature compactness loss和feature separateness loss去实现异常在多样性场景中的区分。
3.解决了重建图像的模糊问题
在MemAE中没有考虑输入同类型的正常场景之间的变化问题和CNN通道容量太大导致的重建模糊问题。本文通过输入的embedding和Memory中所有的embedding进行compact(即输入相似的场景尽量归为同一个项)来解决。
做法
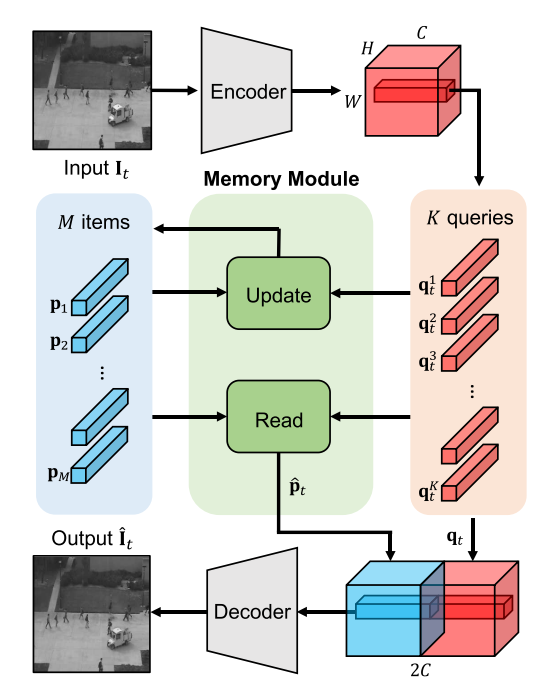
本文提出MNAD模型,该模型由三个主要部分组成,编码器(用于编码输入和生成查询),解码器(用于重建)和记忆模块(包括场相似场景的记忆以及多样性场景之间的区分)。如上图所示,训练时,将正常样本图像经过编码器生成embedding存于Memory中,通过Memory Read和Memory Update生成的embedding和输入的embedding拼接传给decoder进行重建输出。
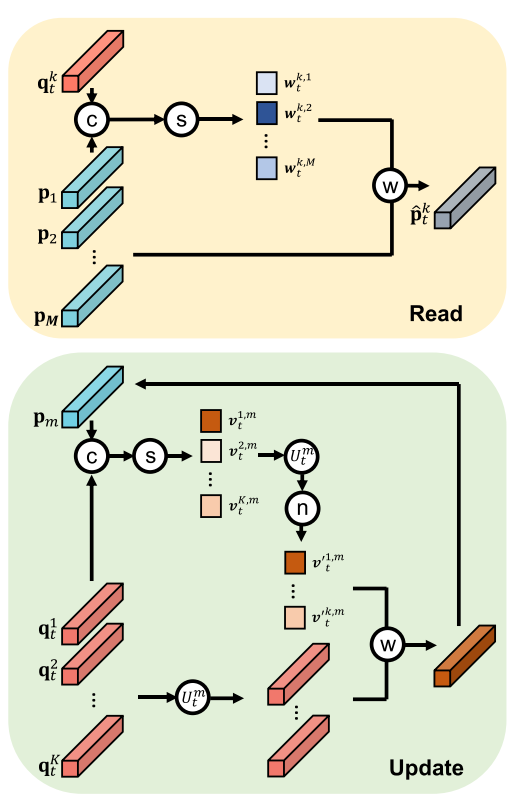
如上图所示,在Memory Read时,当再次输入正常样本时,将输入的某个embedding的向量 $q_t^k$与所有Memory的所有embedding ($p_1,…,p_M$)进行转置和Softmax操作更新权重更新记忆项$\hat p_t^k$,即通过权重更新可使得记忆项中的embedding尽量接近输入的embedding;(主要通过feature compactness loss反映)
feature compactness loss为
$$ L_{compact}=\sum_t^T\sum_k^K\vert\vert q_t^k-p_p\vert\vert_2 $$
该式子表明对于输入图像的embedding $q_t^k$,在记忆项中找到一个$p_p$,使得它们距离越近越好。该loss保证了记忆项中的embedding和输入embedding的一致性。
在Memory Update时,将输入的所有embedding($q_t^1,…,q_t^K$)与某个Memory中的embedding $p_m$进行转置和Softmax操作更新权重更新记忆,即对于同一个输入embedding,权重可反映记忆项之间的差异性,差异性可决定场景的不同。(主要通过feature separateness loss反映)
feature separateness loss为
$$ L_{separate}=\sum_t^T\sum_k^K[\vert\vert q_t^k-p_p\vert\vert_2-\vert\vert q_t^k-p_n\vert\vert_2+\alpha]_+ $$
该式子表明对于输入图像的embedding $q_t^k$,在记忆项中找到距离最近的embedding $p_p$的同时找到距离第二近的$p_n$,从而让输入接近最$p_p$,拉大与$p_n$之间的距离。该loss保证了记忆项中embedding之间的差异应该得拉大,这样做可以增强不同场景的区分和判别能力。
总的训练的loss是
$$ L=L_{rec}+\lambda_cL_{compact}+\lambda_sL_{separate} $$
重构的loss为
$$ L_{rec}=\sum_t^T\vert\vert \hat I_t-I_t\vert\vert_2 $$
其中$T$为视频序列长度,loss为输入与输出的$L_2$距离。
当输入异常时,文中通过函数$P$计算输入帧和重建帧的PSNR值和通过函数$D$输入embedding和Memory的embedding的差距作为异常分数$S_t$来检测异常。用离差标准化$g$的表示形式如下。
$$ S_t=\lambda(1-g(P(\hat I_t,I_t)))+(1-\lambda)g(D(q_t,p)) $$
缺点和问题
1.在异常分割和定位方面,该文章能涉及异常区域的定位,却没有对定位区域实现分割;
2.在模型泛化性能方面,文中对模型的训练使用的都是视频帧,说明网络时也是用前4帧来预测第5帧,当MNAD遇到前后关联性不大的数据集时性能仍是未知。
数据集
1.UCSD-Ped2: http://www.svcl.ucsd.edu/projects/anomaly/dataset.htm
2.CUHK Avenue: http://www.cse.cuhk.edu.hk/leojia/projects/detectabnormal/dataset.html
3.ShanghaiTech: https://svip-lab.github.io/dataset/campus_dataset.html


