论文题目
该文是发表在ICCV 2019的文章,文章标题是通过无监督的方法对自编码器进行记忆增强,让自编码器记住更多正常模式,从而检测输入是否异常。文章解决了什么无监督异常检测的问题呢?
Motivation
1.传统的深度自编码器泛化能力过强
我们知道,深度自编码器(Deep Auto-Encoder)是由一个从输入获得压缩编码的编码器和一个可以从编码中重建数据的解码器组成。编码压缩的本质上是一个迫使网络提取高维数据的信息瓶颈。在无监督异常检测时,通常通过最小化正常数据上的重建误差来训练AE,然后将重建误差用作异常指示。由于正常输入的重建误差接近训练数据,因此重建误差将较低,而异常输入重建后误差则变得较高。
然而,如果某些异常输入与正常训练数据共享共同的成分模式(例如,图像中的局部边缘相似),或者解码器“太强”而无法很好地解码某些异常编码,则AE非常有可能很好地重建异常。换言之,传统的AE(Auto-Encoder)的泛化能力较强,从而导致了输入异常模式时,重构输出后也可能得到长得像正常的异常模式,在检测时会被误分类。
2.缺乏可靠机制拉大对异常的重建
重建的思想是在正常的数据上学习模型,异常不能得到很好的编码与重建。但现有的许多方法(深度自编码器,稀疏表示等)缺乏可靠的机制来鼓励模型不很好地重建异常,即模型不能使得异常有着较大的重建误差。
Contribution
1.对自编码器引入attention机制
为了抑制自编码器的泛化能力过强使得异常得到很好的重建这件事,文中的解决方法有两个,一个是在整个框架中加入Memory模块使得编码器记住更多正常的特征,一个是在Memory模块中引入硬收缩的稀疏寻址来防止记忆项的相关性太强导致异常得到很好的重建。
2.开山之作
经查阅资料,该文是第一篇将attention机制引入无监督异常检测的文章,后续仍具有研究价值。
做法
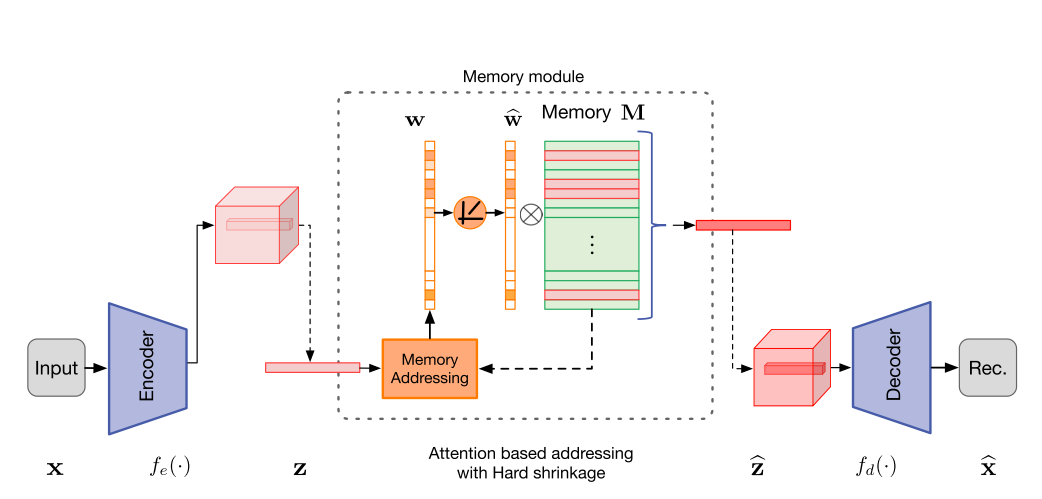
本文提出MemAE模型,该模型由三个主要部分组成,编码器(用于编码输入和生成查询),解码器(用于重构)和记忆模块(带有内存和相关的内存寻址运算符)。如上图所示,训练时,将正常样本图像经过编码器生成embedding存于Meomory中,当再次输入正常样本时,将输入的embedding与Memory中的embedding进行相似度计算(文中采用余弦相似度),再用相似度的Softmax作为权重,用加权求和去更新Memory中的embedding,加入attention机制的目的是让存储器更新时以记录更多正常数据的正常特征,该embedding经解码器后输出重建图像与输出图像进行MSE loss。
在记忆模块中,文章发现Memory中如果embedding过多可能会使得模型的泛化能力提高,这会使得异常会得到很好地重建,因此,文章提出硬收缩的稀疏寻址(Hard Shrinkage for Sparse Addressing)来解决这个问题,该方法保证了寻址权重具有一定的稀疏性。如下公式所示。
$$ \hat\omega_i=\frac{max(w_i-\lambda,0)\cdot\omega_i}{\vert\omega_i-\lambda\vert+\epsilon} $$
给定收缩阈值$\lambda$,当权值大于收缩阈值时,再对权重进行更新。
整个编码器$e$和解码器$d$的loss由重建loss $R$和权重的交叉熵$E$组成。
$$ L(\theta_e,\theta_d,M)=\frac{1}{T}\sum_{t=1}^T(R(x^t,\hat x^t)+\alpha E(\hat\omega^t)) $$
缺点
1.在异常检测方面,据参考资料的总结,文中重建图像比较模糊。可能是因为编码时由于下采样导致部分信息丢失。
2.在异常分割和定位方面,该文章并没有涉及,文中只能区分正常与异常而已。
3.文中对应多场景的异常检测(都是拿着一把刀,在教室里拿着检测为异常,厨房里拿着检测为正常)也没有涉及。
数据集
1.MNIST: http://yann.lecun.com/exdb/mnist/
2.UCSD-Ped2: http://www.svcl.ucsd.edu/projects/anomaly/dataset.htm
3.CUHK Avenue: http://www.cse.cuhk.edu.hk/leojia/projects/detectabnormal/dataset.html
4.ShanghaiTech: https://svip-lab.github.io/dataset/campus_dataset.html
5.KD-DCUP99


